Noindex, nofollow – чек-лист для роботи з контентом і посиланнями
Noindex і nofollow часто називають некоректно: тегами, метатегами, атрибутами. Насправді noindex – це тег, а nofollow – атрибут всередині тега.
Метатеги – це теги, які відносяться до всієї сторінки: <meta name = “robots” content = “noindex, nofollow” />
Тег <noindex> створює конструкцію: <noindex> … </ noindex>;
атрибут rel = “nofollow” може з’являтися в конструкції тега.
За допомогою цих параметрів можна і потрібно вказувати пошуковим роботам Google, Яндекс або інших систем, як саме потрібно взаємодіяти з контентом, що знаходиться всередині цих параметрів.
Де і як використовувати noindex і nofollow
Ці атрибути можуть розташовуватися в “шапці” сторінки, і тоді вони будуть правилом для всього контенту. А можуть захищати конкретний текстовий фрагмент, посилання або зображення.
Для сторінок метатеги noindex і nofollow закривають від індексації:
- сторінки реєстрації;
- службові сторінки;
- сторінки авторів коментарів;
- інші «шкідливі» для індексації сторінки;
Для контенту теги noindex і атрибут nofollow закривають від індексації:
- «шкідливі» посилання;
- цитати з різних джерел;
- повторюваний контент
Щоб закрити від індексації Сторінки – метатеги noindex и nofollow
Коли потрібно, щоб сторінка і контент на ній індексувалися, а пошуковий робот не переходив по посиланнях. В такому випадку використовуємо конструкцію:
<meta name="robots" content="index, nofollow"/>
Коли треба закрити сторінку від індексації, а переходи по посиланнях дозволити, вставляємо
<meta name="robots" content="noindex, follow"/>
Щоб індексувалися і посилання, і сама сторінка, в заголовку застосовуємо метатег
<meta name="robots" content="index, follow"/>
Для повного закриття сторінки і посилань на ній від індексації:
<meta name="robots" content="noindex, nofollow"/>
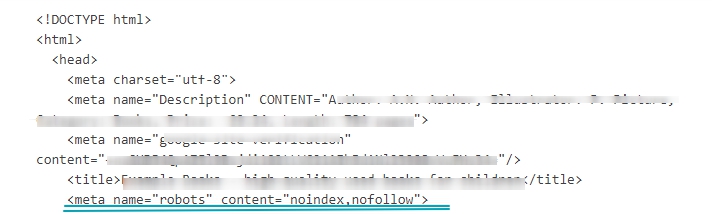
Для прикладу наведемо заголовок сторінки, в якій використовуються метатеги з повним закриттям сторінки і посилань для індексації її роботом пошукової системи (noindex, nofollow):
<html>
<head>
<meta name="robots" content="noindex,nofollow">
<meta name="description" content="Description для сторінки">
<title>…</title>
</head>
<body>
Для контенту і посилань тег noindex і атрибут nofollow
Щоб приховати від індексації фрагмент тексту (працює тільки для Яндекс і Рамблер), використовуємо наступне рішення:
<!--noindex--> (текст) <!--/noindex-->

Щоб приховати від індексації посилання, використовуємо:
<a href="https://mysite.com/" rel="nofollow">Текст ссилки </a>
Щоб приховати посилання від індексації і Яндекс, і Google, застосовуємо
<noindex><a href="http://mysite.com/" rel="nofollow">текст ссилки</a></noindex>
Google в даній конструкції приймає тільки rel = “nofollow”, а для Яндекса діють і noindex, і rel = “nofollow”.
<noindex> — неофіційний тег
<noindex>…</noindex> використовується пошуковими системами Яндекс і Rambler. Мета – приховати від індексації зазначений контент.
Google на цей тег не звертає увагу, бо він не є прийнятим тегом розмітки html.
rel=”nofollow” — атрибут всередині тега посилання
rel=”nofollow” забороняє пошуковим системам переходити за вказаним URL. Конструкція:
<a href="signin.php" rel="nofollow">Увійти</a>
Як повідомляється у відповіді підтримки Google для веб-майстрів, пошукова система не переходить за посиланням і не використовує для переходу по ній краулінговий бюджет. Але це не означає, що робот туди не загляне, і не перевірить. Тобто подальша доля цього посилання така: ми про тебе знаємо, але мовчимо, поки це безпечно.
Якщо потрібно приховати від індексації сторінки тільки для Google, можна використовувати <meta name=”googlebot” content=”noindex” />.
Якщо потрібно закрити від індексації тільки для Яндекс – <meta name=”yandex” content=”noindex”/>.
Закриття індексації через файл robots.txt
Метатеги, описані раніше, <meta name = “robots” content = “noindex, nofollow”> з’являються тільки після відкриття роботом сторінки і прочитання заголовка.
Закриття ж сторінки через файл robots.txt забороняє навіть заходити на сторінку.
Якщо пошукова система раніше проіндексувала цю сторінку, то вона буде знаходиться в індексі пошукових систем (навіть після закриття в файлі robots.txt). А в description нам повідомлять, що опис для цієї сторінки відобразити неможливо, адже вона закрита від індексації у файлі robots.txt.
# robots.txt for http://www.w3.org/
User-agent: W3C-gsa
Disallow: /Out-Of-Date
User-agent: W3T_SE
Disallow: /Out-Of-Date
User-agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT; MS Search 4.0 Robot)
Disallow: /
# W3C Link checker
User-agent: W3C-checklink
Disallow:
User-agent: Applebot
Disallow: /People/domain/
# the following settings apply to all bots
User-agent: *
# Blogs - WordPress
# https://codex.wordpress.org/Search_Engine_Optimization_for_WordPress#Robots.txt_Optimization
Disallow: /*/wp-admin/
Disallow: /*/wp-includes/
Disallow: /*/wp-content/plugins/
Disallow: /*/wp-content/cache/
Disallow: /*/wp-content/themes/
Disallow: /blog/*/trackback/
Disallow: /blog/*/feed/
Disallow: /blog/*/comments/
Disallow: /blog/*/category/*/*
Disallow: /blog/*/*/trackback/
Disallow: /blog/*/*/feed/
Disallow: /blog/*/*/comments/
Disallow: /blog/*/*?
Тому для непроіндексованих сторінок можна використовувати, як варіант, закриття через метатеги в заголовку, так і через файл роботс.тхт.
Якщо сторінка вже була проіндексована, рекомендуємо вставити в заголовок, в секцію <head> метатег <meta name = “robots” content = “noindex, nofollow” />. Це виключить її з індексації і дасть змогу запобігти подальшому потраплянню в неї.
В цьому файлі є кілька блоків. Перший – User-agent – команда для визначення робота, до якого можна віднести наступні директиви. У коді файлу роботс.тхт, що представлений вище – для робота W3C-gsa, W3T_SE, Mozilla / 4.0, W3C-checklink, Applebot. А зірочка (*) після команди User-agent – говорить що наступні директиви відносяться до всіх пошукових роботів. В більшості випадків нам знадобитися заголовок у файлі robots.txt наступного стандартного вигляду:
User-agent: * # applies to all robots
Наступні директиви дозволяють виключити, як окремі сторінки, так і цілі папки зі сторінками. Код буде виглядати так:
Disallow: / # disallow indexing of all pages
У разі, якщо в цій папці є одна або кілька сторінок, які повинні буті проіндексовані, чинимо так:
User-agent: *
Disallow: /help #забороняє сторінки до індексування, які знаходяться в каталозі, наприклад: /help.html и /help/index.html
Disallow: /help/ #забороняє тільки ті сторінки, які знаходяться на рівень нижче каталогу help, а ті, що в цьому каталозі - залишаються відкритими, наприклад: /help/index.html закритий, але /help.html - відкритий
У файлі robots.txt обов’язково має бути хоча б одне поле Disallow. Як же бути, якщо нам не потрібно закривати жодної сторінки? Ми залишаємо поле порожнім:
Disallow: # якщо після директиви залишити поле порожнім – вважається, що всі сторінки сайту залишаються відкритими для індексування
Поширені помилки:
Спроба закрити від індексації посилання наступною комбінацією: <nofollow> <a href=”index.php”> Перейти </a> </ nofollow>
Тег <noindex> для розмітки html є неофіційним; в офіційній розмітці є тільки атрибут rel або метатег зі значенням nofollow.
Спроба закрити посилання від індексації за допомогою тега <noindex>. Таким чином можна закрити тільки анкор (текст посилання, а не саме посилання), і тільки для Яндекс.
Висновки
Для економії краулінгового бюджету важливо закривати від індексації зайві посилання, вага яких не суттєва для просування.
Для пошукових систем посилання nofolow виглядають природно, а їх наявність є нормальною. Однак велика кількість вихідних посилань на сайті може виявитися і мінусом, незважаючи на те, що вони були закриті від індексації.